DeepSeek R1, a state-of-the-art open model, is now available. Try it now!
Introduction
Sourcegraph helps enterprises industrialize software development with AI. They have empowered developers with enterprise-grade code search and analysis for over a decade at companies like Stripe, Uber, government organizations, and top US banks. With the increasing demand for AI-driven coding assistants, Sourcegraph’s AI is designed to enhance code understanding and developer productivity even further.
To meet the high-performance demands of enterprise clients and the broader developer community, Sourcegraph sought a scalable, flexible, and cost-effective platform capable of integrating multiple Large Language Models (LLMs) while maintaining real-time performance.
Company background
- Market position and audience: With 12 years in operation, Sourcegraph serves software engineering teams and leaders as the go-to provider for enterprise-grade code search across vast and complex repositories, accelerating how the biggest companies in the world build software.
- Core focus and adoption: Focused on delivering enterprise-grade code search and navigation across multi-language, multi-repository environments, Sourcegraph is trusted by Fortune 500 companies and leading tech organizations managing billions of lines of code.
- Differentiators and challenges: Known for its comprehensive code intelligence, seamless developer workflow integrations, and commitment to open-source, Sourcegraph addresses the challenge of scaling performance and usability as codebases grow exponentially.
- Role of AI: Sourcegraph automates routine tasks and workflows that developers perform with AI agents and a contextual understanding of large codebases, freeing devs of soul-sucking work and accelerating their ability to innovate.
Results
Sourcegraph partnered with Fireworks to elevate their AI’s impact by addressing the unique challenges of scaling performance, enhancing usability, and integrating advanced AI capabilities,.
This collaboration delivered transformative results, driving significant improvements in latency, efficiency, and developer experience.
- Performance gains:
- 30% reduction in latency: Achieved via advanced inference optimizations.
- 2.5× increase in acceptance rate: CAR improved from 15% to 40%.
- 40% increase in context length: Supported more extensive context without additional latency.
- Cost efficiency: Flexible infrastructure options led to substantial savings.
- Enhanced user experience: Developers benefited from faster, higher-quality code completions.
- Rapid innovation: Faster deployment cycles kept Sourcegraph ahead of competitors.
The challenge
To achieve transformative results, Sourcegraph faced several challenges when optimizing for a seamless and high-performing user experience:
- Real-time performance: Sub-second latency was essential for features like multi-line code completion and autopilot-like coding assistance.
- Model limitations: Other models were optimized for chat, not code completion, leading to quality issues.
- Context handling: The need to process 1–2k tokens of context and generate 50–100 tokens of completion swiftly.
- Cost management: Maintaining high performance while controlling costs was key to staying competitive.
Alternatives explored
Before partnering with Fireworks, Sourcegraph considered:
- Single LLM providers: Other models couldn’t consistently meet sub-second latency requirements.
- Open-source models: Models like StarCoder and WizardCoder 15B had latency issues, even on advanced hardware.
- Model fine-tuning: Fine-tuning was deemed impractical short-term due to time and resource constraints.
- Self-hosting: Operational complexity and scalability challenges made self-hosting less viable.
None of these options fully addressed the need for flexibility, performance, and cost-effectiveness.
The solution
Fireworks delivered a comprehensive solution:
- Model flexibility: Fireworks supports a wide range of LLMs, enabling Sourcegraph to seamlessly integrate and test models like DeepSeek-Coder-V2 and StarCoder. The ability to quickly evaluate new models sped up iteration cycles and avoided vendor lock-in.
- High performance: Through optimizations like Flash Attention-2, prompt speculation, and direct routing, Sourcegraph achieved sub-second latency even with extensive context handling.
- Open-source model integration: Fireworks’ robust support for OSS models allowed Sourcegraph to evaluate and deploy models offline rapidly, improving completion acceptance rates (CAR) from 15% to 40%.
- Cost-effectiveness: Flexible pricing models—serverless, on-demand, and enterprise reserved GPUs—optimized infrastructure usage and lowered costs.
Implementation
The integration process with Fireworks was smooth and collaborative:
- Optimized infrastructure: Leveraging Fireworks’ FireAttention and FireOptimizer technologies ensured high performance with minimal latency.
- Dynamic model selection: Real-time performance data guided the selection of optimal LLMs, maintaining consistent quality.
- Accelerated deployment: Reduced deployment time for open-source models from four months to under one month.
- Tailored support: Fireworks’ team provided critical optimizations, including prompt caching, speculative decoding, and enterprise-grade enhancements like long-prompt optimization.
- Early advocacy and engagement: CTO Beyang Liu and product engineer Phillip Spies were strong proponents of Fireworks, fostering a close collaboration that helped identify key opportunities for optimization.
Customer insights
Sourcegraph's collaboration with Fireworks provided not only technical benefits but also valuable insights that further enhanced their AI’s capabilities, according to Hitesh Sagtani, MLE at Sourcegraph:
- Speed of iteration: “Fireworks’ quick support for open-source models and their ability to add newly released models rapidly allowed us to evaluate candidates offline efficiently. This significantly sped up our iteration cycles.”
- Key differentiators: “The collaborative spirit of the Fireworks team was unmatched. They helped with critical inference optimizations like Flash Attention-2, n-gram speculative decoding, and benchmarking optimal replicas and shards for DS-Coder-2.”
- Implementation support: “Enterprise optimizations like prompt speculation and training a draft model for speculative decoding were game-changers for reducing latency.”
- Evolving use: “The responsiveness of the Fireworks team and their fast query resolution have been remarkable. It’s been a pleasure to work with such an efficient and supportive partner.”
Beyang Liu, CTO of Sourcegraph, highlights the transformative impact of Fireworks as a trusted partner in advancing AI-powered developer tools and ensuring Sourcegraph’s position as the best AI coding assistant for the enterprise.
“Fireworks has been a fantastic partner in building AI dev tools at Sourcegraph. Their fast, reliable model inference lets us focus on fine-tuning, AI-powered code search, and deep code context, making Sourcegraph the best AI coding assistant. They are responsive and ship at an amazing pace.”
Lessons learned
The collaboration between Sourcegraph and Fireworks revealed key strategies and best practices that drove their success, offering valuable lessons for building high-performance, AI-driven solutions.
- Optimize extensively: Advanced techniques like FireAttention and speculative decoding can dramatically improve latency and user experience.
- Leverage model flexibility: Incorporating specialized and OSS models accelerates iteration and enhances performance.
- Collaborate closely: Strong partnerships drive faster innovation and better solutions.
- Stay agile: Rapid deployment and flexible infrastructure are critical for maintaining a competitive edge.
Conclusion
By partnering with Fireworks, Sourcegraph elevated their AI capabilities to deliver real-time, high-quality code assistance for engineering teams at the biggest companies in the world. Fireworks’ innovative Compound AI platform has empowered Sourcegraph to meet the evolving needs of enterprise developers and maintain its position as a leader in developer tooling. Together, they’re setting a new standard for AI-driven coding assistants.
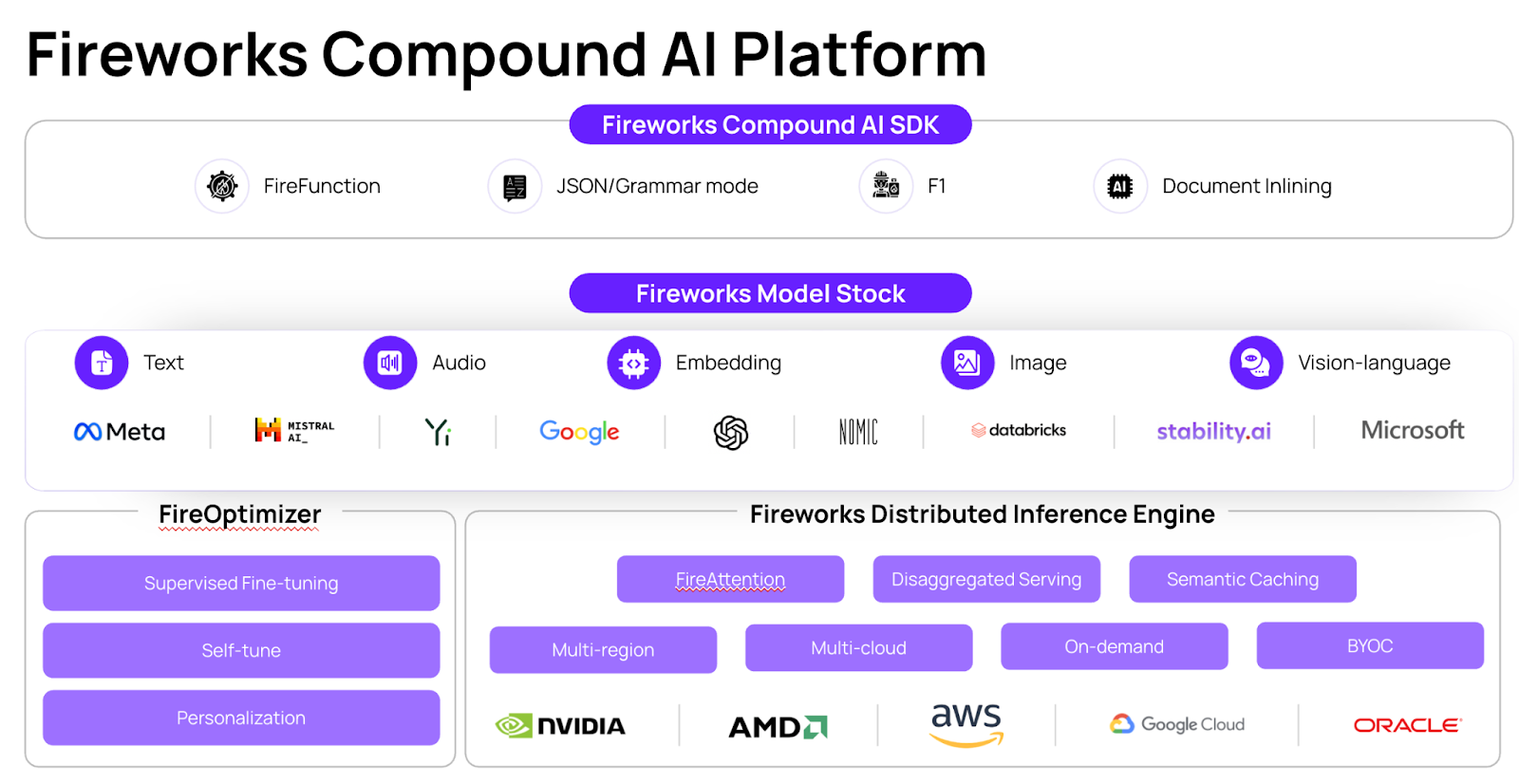
Build smarter through Compound AI
Fireworks makes it easy to build compound AI systems, by providing one place for:
- Inference: Run all types of models and components fast and cost-effectively
- Models and modalities: Get all the models you need for your system in one place, across modalities like text, audio, image and vision understanding
- Adaptability: Tune and optimize models for quality and speed to suit your use case
- Compound AI: Coordinate and run components together by using Fireworks frameworks and tools like function calling and JSON mode
Keep in touch with us on Discord or Twitter. Stay tuned for more updates coming soon!
